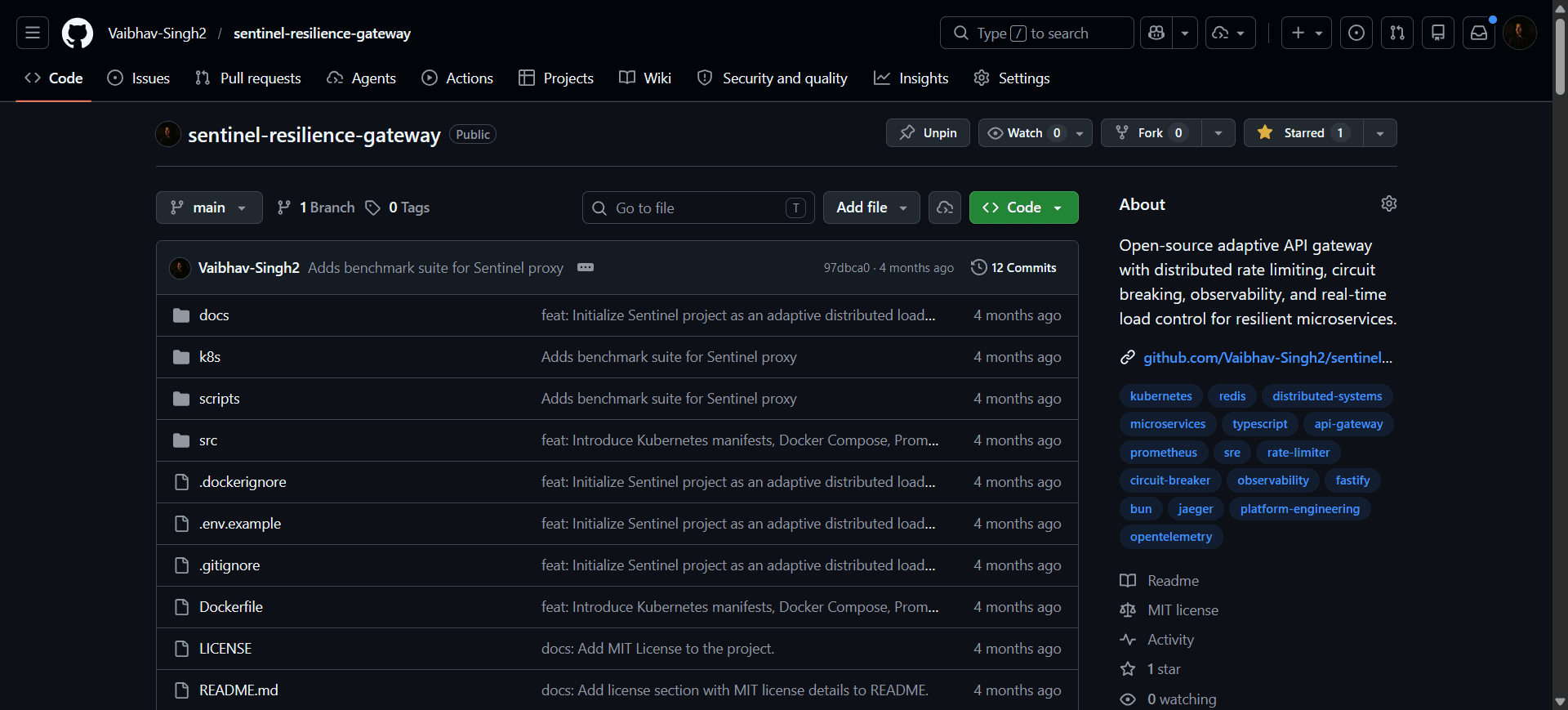
Sentinel — Adaptive Distributed Load Control Microservice
Open-source adaptive HTTP reverse proxy in TypeScript/Bun, sustaining ~6,800 req/s at p99 41ms baseline. Protects distributed backends from traffic spikes and cascading failures via hybrid rate limiting, distributed circuit breaking, and real-time pressure-based throttling.
More Projects
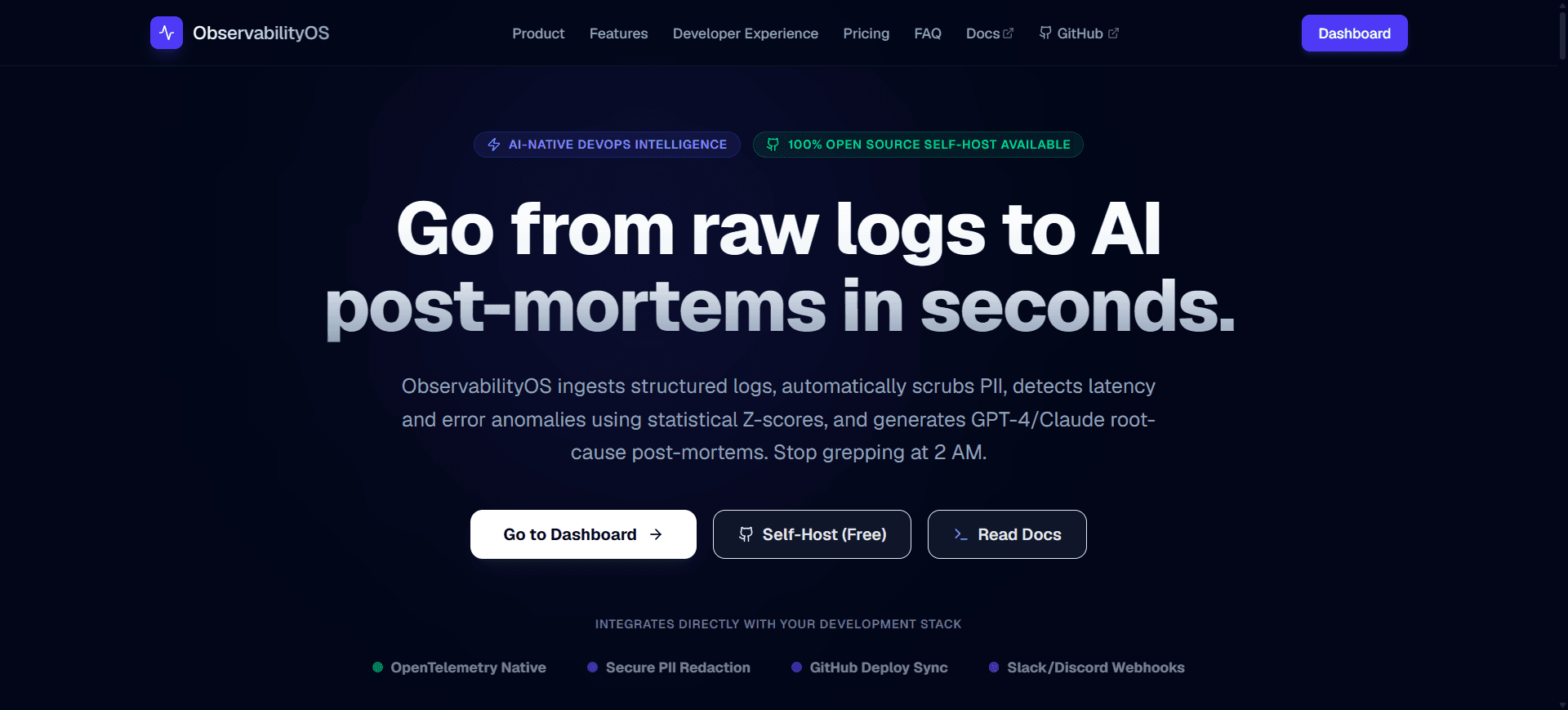
ObservabilityOS — AI-Native DevOps Intelligence & Observability Platform
AI-native log analytics and incident response platform with real-time streaming, statistical anomaly detection, and multi-provider LLM diagnostics.
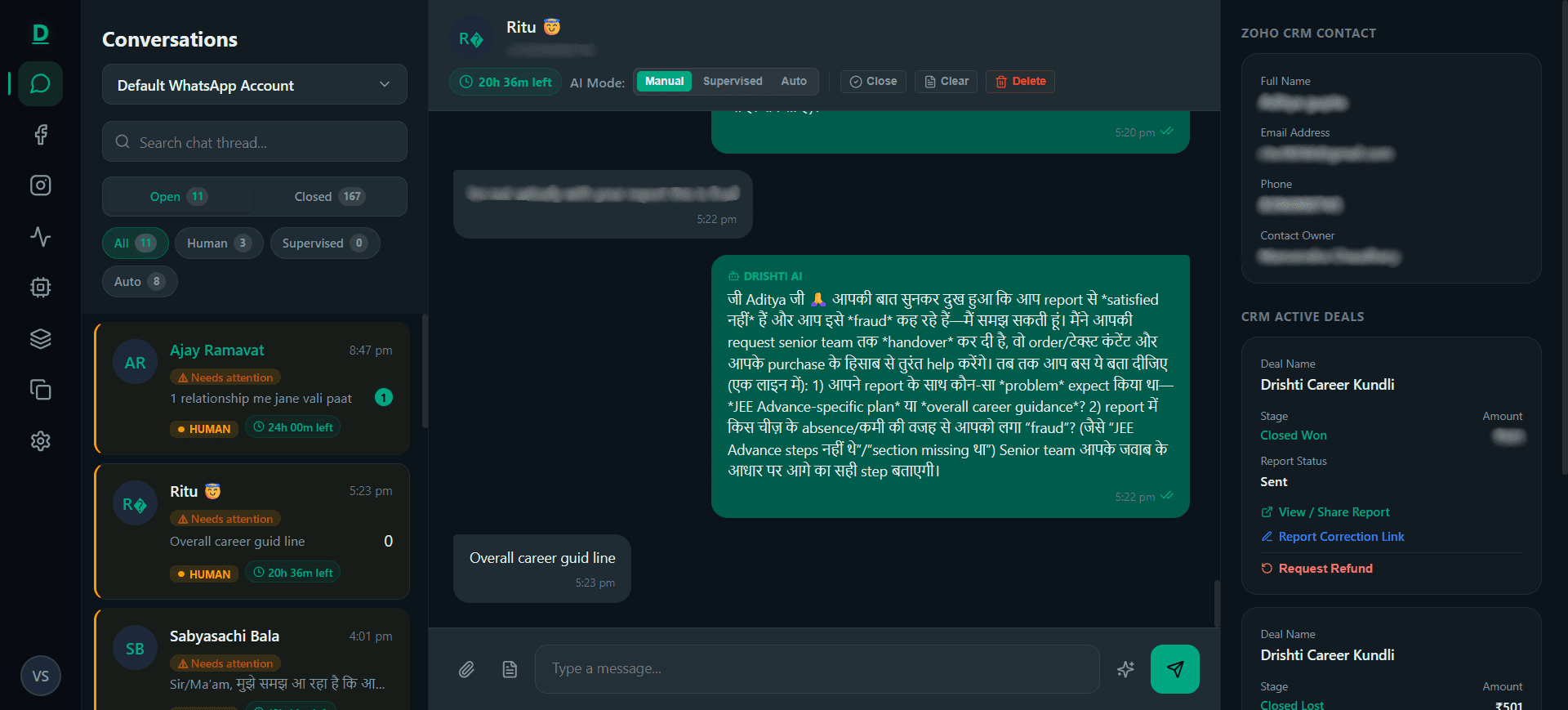
Drishti Marketing OS — Enterprise WhatsApp AI Agent Platform
Enterprise WhatsApp Business inbox replacing third-party BSPs with a custom Meta Cloud API integration, multi-provider AI agent (Claude/GPT-4o/Gemini), RAG knowledge base, and real-time Zoho CRM data — achieving 89.7% AI self-service rate and 96% reduction in lead response time.
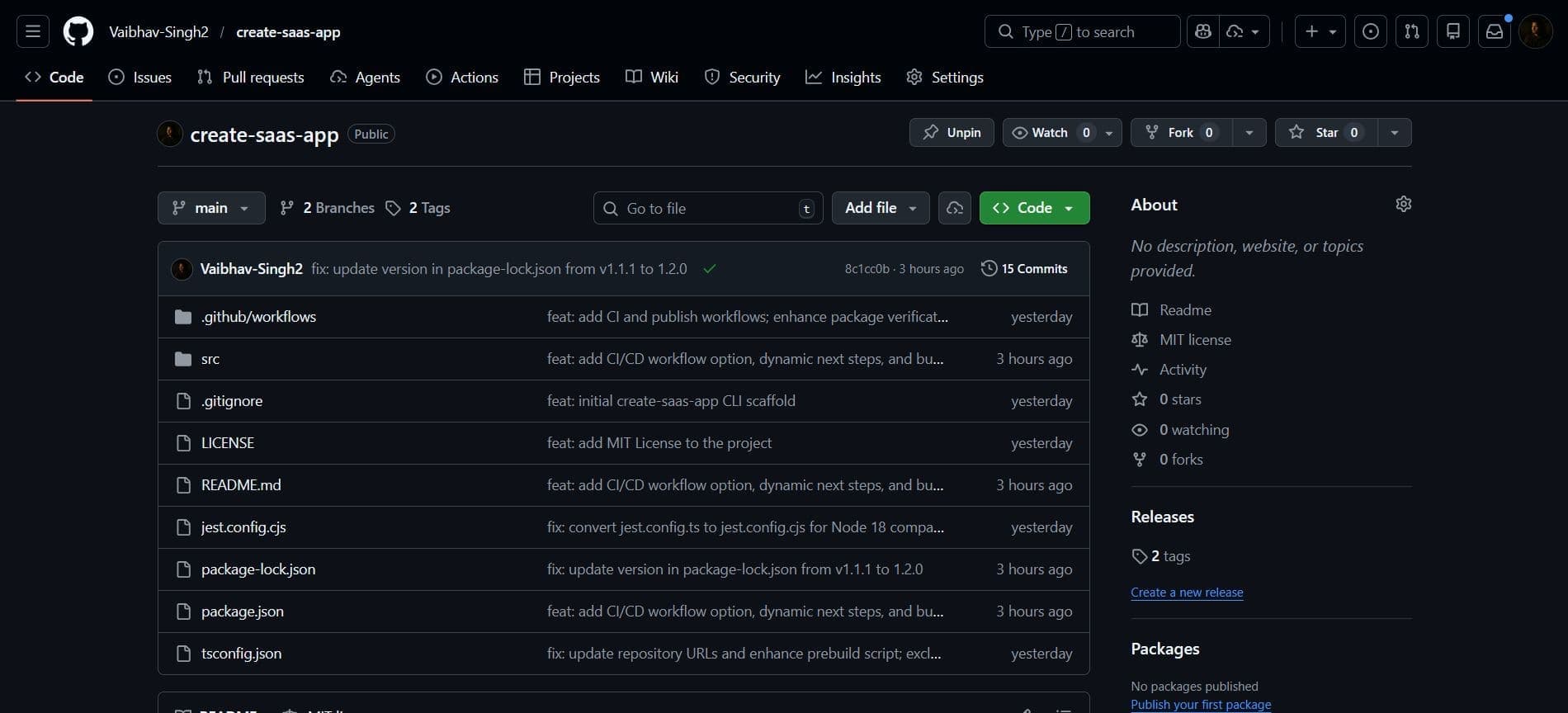
create-saas-app · Modern SaaS Monorepo Boilerplate
Open-source interactive CLI (npx create-saas-app-cli) that scaffolds a fully-configured Turborepo monorepo in seconds — with database, auth, queues, payments, observability, and CI/CD selected interactively at prompt time.